You will want to use the Gantt chart data in other applications such as Excel, Google Sheets, or Jira.
Gantt Chart Planner for Confluence provides the CSV data export feature to achieve it.
How to export data as CSV
-
Open CSV export dialog
-
Select options
-
Click the Export button. Then, you can download a CSV file.
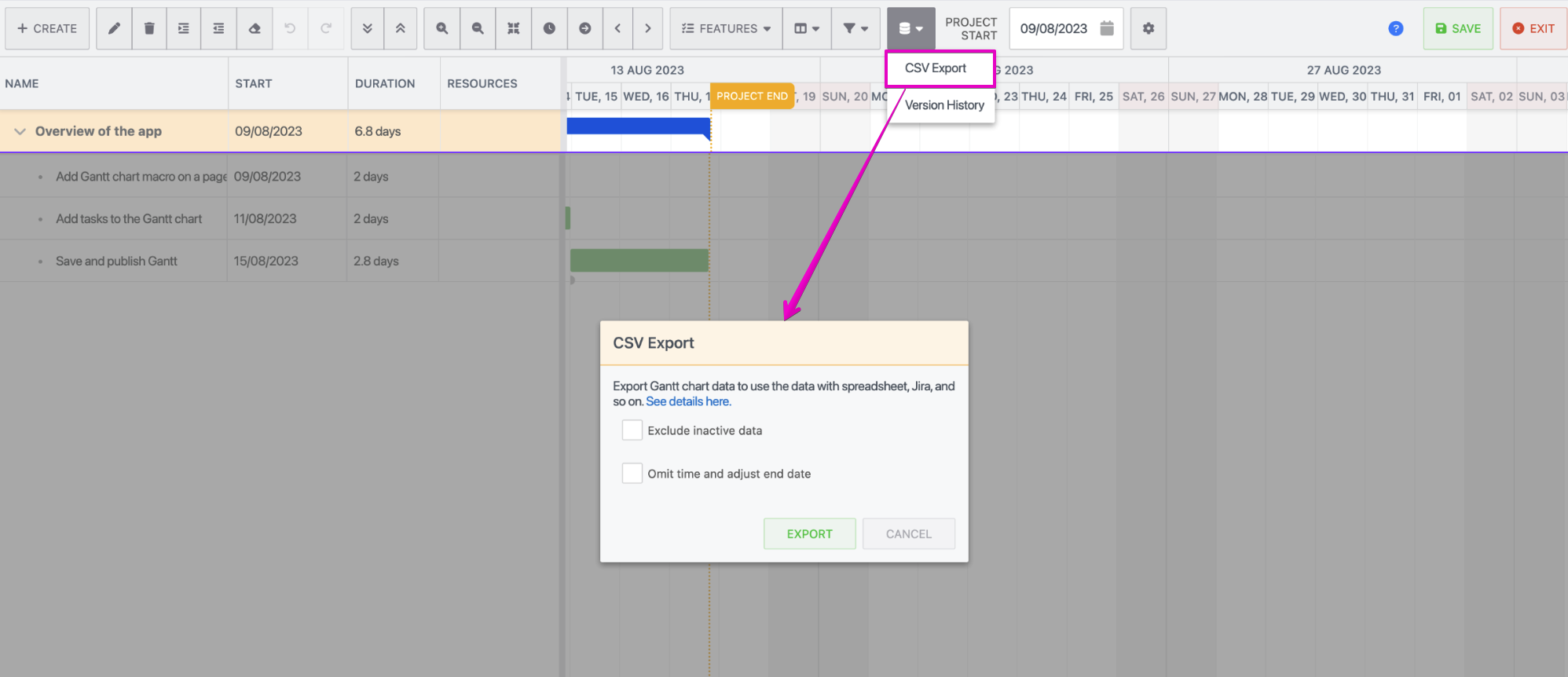
CSV Export options
|
Option |
Description |
|---|---|
|
Exclude inactive data |
Check this option to exclude inactive data from the CSV file.
|
|
Omit time and adjust end date |
Check this option if you want to omit time values for all date columns to use CSV data in the application that doesn’t support time values like Jira. If you check this option, except for milestone tasks, end date values, including baseline end date, deadline date, and end date constraints, at midnight will be the previous date to keep the actual date. e.g.
|
CSV file format
Character code
Character code is UTF-8 with BOM.
Row
Each row represents each task.
Columns
|
Column Name |
Description |
|---|---|
|
id |
ID of the task. It’s a unique number in the single Gantt chart. |
|
wbsCode |
Dot separated number that represents task sequence in the hierarchy. |
|
name |
Name of the task. |
|
startDate |
Start date of the task. |
|
endDate |
End date of the task. |
|
duration |
Duration of the task. Please note that the duration unit will be the day unit even if you set other duration units. |
|
Resource **
|
Assigned resources.
|
|
percentDone |
% Done of the task. |
|
constraintType |
Constraint type of the task.
|
|
constraintDate |
Constraint Date of the task. |
|
deadlineDate |
Deadline Date of the task. |
|
manuallyScheduled |
If manually scheduled is enabled for the task, it will be “true”. Otherwise, it will be “false”. |
|
rollup |
If rollup is enabled for the task, it will be “true”. Otherwise, it will be “false”. |
|
defaultCollapse |
If default collapse is enabled for the task, it will be “true”. Otherwise, it will be “false”. |
|
inactive |
If task is inactive, it will be “true”. Otherwise, it will be “false”. |
|
color |
Color of the task. |
|
propagateColor |
If propagate color is enabled for the task, it will be “true”. Otherwise, it will be “false”. |
|
webLink |
Weblink of the task. |
|
note |
Note of the task. |
|
milestone |
If task is a milestone, it will be “true”. Otherwise, it will be “false”. |
|
baselineStartDate |
Baseline start date of the task. |
|
baselineEndDate |
Baseline end date of the task. |
|
parentId |
Task id of the parent task. |
|
childId ** |
Task ids of the children. |
|
level |
The hierarchy level that the task is in. 1 means the top level. |
|
jiraIssueType |
This is for recommended Jira issue type when importing data into Jira.
|
|
jiraEpicName |
This is for setting epic name field value when importing data into Jira.
|
|
jiraEpicLink |
This is for setting epic link field value when importing data into Jira.
|
|
jiraSubtaskParentId |
This is for setting sub-tasks’s parent id when importing data into Jira.
|
|
mainResource
|
The main resource is an assigned resource that has the largest units. If multiple resources have the largest units, the resource that has the least alphabetically ordered name will be the main resource.
|
|
predecessors **
|
Predecessors of the task.
|
|
successors **
|
Successors of the task.
|
** This column is repeated for the count of source properties.
*** Dependency type will be one of the SS, SF, FS, or FF. SS means Start-to-Start. SF means Start-to-Finish. FS means Finish-to-Start. FF means Finish-to-Finish.
How to import CSV data into Jira
You would want to import Gantt chart data into Jira if you plan a project in Confluence, then manage the project in Jira.
Here is how to import CSV Gantt chart data into Jira to use the data with Advanced Roadmaps or third-party Gantt chart apps like WBS Gantt-Chart for Jira.
To import CSV data into Jira, you use the CSV import feature of Jira.
Steps to import CSV data into Jira
Please watch the demo video to see the details.
Export CSV data from Gantt Chart Planner
-
Open the Gantt chart you want to export the data.
-
Open CSV export dialog. And check “Exclude inactive data“ and “Omit time and adjust end date“.
-
Click “Export“ and download the CSV file.
Import CSV data into Jira
-
Select Issues > Import issues from CSV.
-
Choose the exported CSV file. If you have imported other Gantt chart CSV data and downloaded the configuration file, check the “Use an existing configuration file” and upload the configuration file. Then, click “Next”.
-
Fill out the form, then click “Next“.
-
Import to Project → Select the project you want to import the Gantt chart data.
-
File encoding → “UTF-8”
-
Delimiter → “,”
-
Date format → “yyyy-MM-dd“
-
-
Map CSV fIelds to Jira fields, then click “Next“.
See the Field mappings section below to find how to map them. -
Map CSV field values to Jira field values, then click “Validate“.
-
Check if no errors and warnings are found.
Please ignore “Parent Issue cannot be null“ errors. -
Click “Begin Import“.
-
Check if no errors and warnings are found.
-
If you download the configuration file, you can skip the field mappings by using the file in the future importing.
Field mappings
There are two ways to construct WBS in Jira. You have to select which way you use.
Field mappings from CSV fields to Jira fields depend on which way you select.
-
Epic/Story/Sub-task hierarchy
-
Issue link hierarchy
|
Method |
Pros/Cons |
Supported by |
|---|---|---|
|
Epic/Story/Sub-task |
|
|
|
Issue link |
Opposite of the above. |
|
Field mappings to use epic/story/sub-task hierarchy
|
CSV column |
Jira field |
Map field value |
Note |
|---|---|---|---|
|
jiraEpicLink |
Epic Link |
No |
|
|
jiraEpicName |
Epic Name |
No |
|
|
jiraIssueType |
Issue Type |
Yes |
Field value mappings should be,
|
|
jiraSubtaskParentId |
Parent Id |
No |
|
Field mappings to use issue link hierarchy
|
CSV column |
Jira field |
Map field value |
Note |
|---|---|---|---|
|
childId |
Issue link for hierarchy |
No |
If direction of the hierarchy issue link is from children to parent, use parentId CSV column instead. |
|
level |
Issue Type |
Yes |
|
Common field mappings
The table below shows the mapping of fields that are not related to the representation of the hierarchy.
|
CSV column |
Jira field |
Map field value |
Note |
|---|---|---|---|
|
id |
Issue id |
No |
|
|
name |
Summary |
No |
|
|
note |
Description |
No |
|
|
mainResourceAtlassianId |
Assignee |
No |
|
|
startDate |
Field for start date |
No |
|
|
endDate |
Field for end date |
No |
|
|
deadlineDate |
Due Date |
No |
|
|
successorToId |
Issue link for hierarchy |
No |
If direction of the dependency issue link is from the succeeding task to the preceding task, use the predecessorFromId CSV column instead. |
|
baselineStartDate |
Field for baseline start date |
No |
|
|
baselineEndDate |
Field for baseline start date |
No |
|
|
mainResourceUnits |
Field for work assignment ratio |
No |
|
|
manuallyScheduled |
Field for manually scheduled |
Yes |
|
|
milestone |
Field for milestone |
Yes |
|
|
percentDone |
Field for progress |
No |
|
** It’s for default settings. It depends on the configuration of Advanced Roadmaps.
*** It assumes WBS Gantt-Chart for Jira’s issue configuration is below.
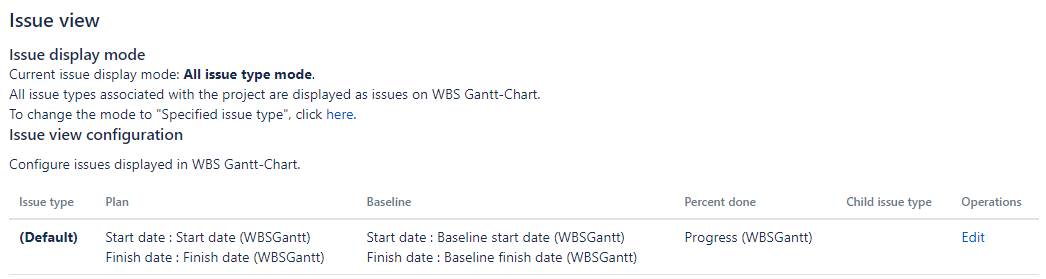
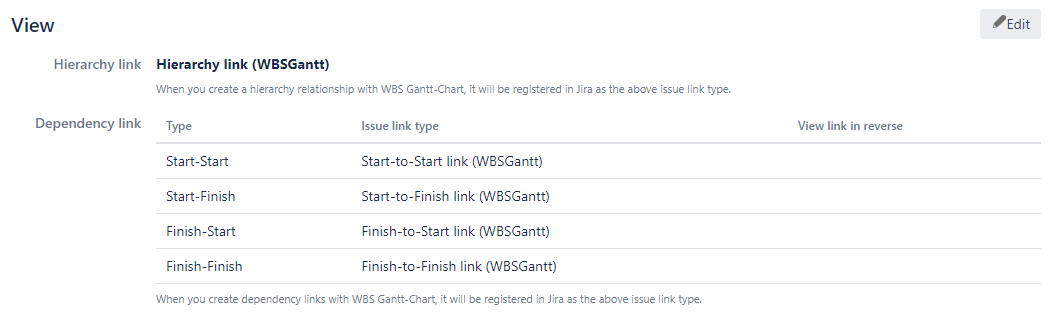
FAQ about importing CSV into Jira
Q: Can’t find Jira fields in field mappings
Jira fields to map have to be placed on create issue screen of the issue types you create.